

Dans cet article, nous abordons la structuration automatique des logs et son importance pour la détection des anomalies. Ces travaux sont issus d’une collaboration entre le laboratoire de recherche LISITE-ISEP et 3DS OUTSCALE. Ceux-ci ont été présentés au cours de la dernière édition de la conférence scientifique IEEE International Conference of Data Mining.
Comme nous l’avons vu dans notre précédent article, les logs sont les journaux de bord des systèmes informatiques. Ils ont pour principal objectif l’horodatage et le stockage de l’historique des événements et des informations correspondantes tels que la tâche en cours d’exécution, le système concerné, le niveau de criticité ou une partie de l’état du système. Par exemple, la ligne suivante correspond à un message de log au sujet d’un nouveau processus déclenché par le serviceManager :
2020-03-19T15:38:55,977 - serviceManager - INFO - New process started: process x92 started on port 42
Ces messages de logs étaient traditionnellement consultés pour la détection des pannes informatiques ou la résolution des bugs de développement. Au cours des dernières années, sous l’impulsion du Big Data, les logs se sont avérés être une source significative d’informations pour d’autres activités telles que la surveillance de la latence des applications, le renforcement des audits de sécurité, ou encore la compréhension du parcours client dans le domaine de la Business Intelligence.
Le Big Data a un impact majeur sur l’analyse des logs. En effet, le volume généré a nettement augmenté dans nos infrastructures (75 % de croissance en 2018, 50 % en 2019). Cette augmentation a deux causes : d’une part la croissance naturelle des infrastructures, d’une autre, l’intérêt suscité par les résultats obtenus. Les utilisateurs encouragent la production de plus de logs lorsqu’ils en découvrent l’utilité.
Pour être analysés, les logs requièrent d’être structurés afin de mettre en avant des parties comparables. Dans l’exemple précédent, nous retrouvons des parties stables et structurées comme la date (2020-03-19T15:38:55,977), l’application concernée (serviceManager) et le niveau de criticité (INFO). Cependant, le contenu du message (New process started: process x92 started on port 42) correspond à du texte libre généré dans le code et risque d’évoluer dans le temps avec les différentes versions logicielles.
Pour illustrer la complexité de la structuration du message libre, nous avons inclus ci-dessous deux messages provenant d’équipements partenaires :
NetApp1 :
monitor.globalStatus.ok: The system's global status is normal. vifmgr.portup: A link up event was received on node node1, port e0c.
Cisco2 :
%LINK-3-UPDOWN: Interface Port-channel1, changed state to up %LINEPROTO-5-UPDOWN: Line protocol on Interface Vlan1, changed state to down %SYS-5-CONFIG_I: Configured from console by vty2 (10.34.195.36)
Nous observons tout d’abord que le format des messages dépend de leur origine. Deuxièmement, les messages issus d’une même source suivent une multitude de patrons différents (c’est-à-dire une expression comme New process started process * started on port *, telle qu’utilisée dans notre premier exemple). Finalement, les variables injectées dans le patron peuvent être des chiffres ou des mots. Un même mot peut être utilisé dans un patron ou dans une variable selon le type de message dans lequel il se trouve.
Dans notre infrastructure, la production de logs est assurée par les différents systèmes de notre stack : notre système d’exploitation Cloud TINA OS, les middlewares utilisés, les équipements physiques, etc. La structure des messages de logs échappe alors à notre contrôle. Par ailleurs, nous n’aurions aucun intérêt à brider une source d’information aussi riche en imposant des contraintes de formatage susceptibles de décourager leur génération. Nous voulons donc un algorithme de structuration qui soit robuste aux comportements des différents systèmes et à leurs évolutions.
La structuration des logs consiste à repérer, en temps réel, le patron et les variables pour chaque log, sachant que le nombre de messages produits est important et que ces messages proviennent de plusieurs systèmes. Bien que ce problème ait déjà été étudié dans la littérature scientifique, les solutions proposées aujourd’hui ne répondent pas aux attentes de nos infrastructures en termes de précision, de robustesse, de latence et de scalabilité.
USTEP : un arbre de recherche évolutif pour la structuration
Pour atteindre ces objectifs de précision et de robustesse, nous proposons USTEP, un algorithme de structuration des logs basé sur un arbre évolutif. Les feuilles de l’arbre vont stocker les patrons, et les logs parcourent l’arbre pour trouver la feuille la plus adéquate. USTEP choisit ensuite le patron qui représente le mieux le message traité. Si aucun ne convient, un nouveau patron est créé à partir des logs actuels. Dans ce processus, deux aspects sont clés : la manière de parcourir l’arbre et le processus d’évolution de la structure arborescente.
Pour le parcours d’arbre, USTEP va tout d’abord exploiter l’hypothèse selon laquelle des logs ayant le même patron vont avoir le même nombre de mots. La suite de la descente est régie par des règles découvertes par le système et concernant des positions importantes dans la distinction des patrons. Notre évaluation met en valeur la pertinence de nos hypothèses, USTEP étant plus précis et plus robuste que les algorithmes de l’état de l’art, avec une précision de 93 % en moyenne contre 90 % pour Drain3, une solution proposée par des chercheurs de l’Université chinoise de Hong Kong en 2017 et servant actuellement de référence.
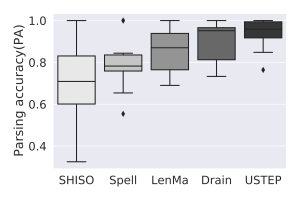 Notre évaluation a porté sur 13 jeux de données en accès libre issus de différents systèmes en accès libre (Android, HDFS, OpenStack, etc.). Les algorithmes de l’état de l’art présentent une forte variabilité selon le jeu de données. Cette variabilité est dangereuse dans un scénario comme le nôtre où différents systèmes de logs cohabitent et évoluent indépendamment de notre contrôle. Dans la figure ci-contre, nous présentons la dispersion de 5 algorithmes sur les jeux de données considérés. Le meilleur scénario possible a lieu quand la boîte est étroite (c’est-à-dire peu impactée par les caractéristiques du jeu de données) et à une position haute (meilleure précision moyenne). Au vu des résultats, USTEP apparaît comme l’algorithme le plus robuste et le moins influencé par la nature des jeux de données. Afin de permettre une meilleure reproduction de nos travaux et de les transmettre à la communauté, le code source d’USTEP est disponible sur GitHub.
Notre évaluation a porté sur 13 jeux de données en accès libre issus de différents systèmes en accès libre (Android, HDFS, OpenStack, etc.). Les algorithmes de l’état de l’art présentent une forte variabilité selon le jeu de données. Cette variabilité est dangereuse dans un scénario comme le nôtre où différents systèmes de logs cohabitent et évoluent indépendamment de notre contrôle. Dans la figure ci-contre, nous présentons la dispersion de 5 algorithmes sur les jeux de données considérés. Le meilleur scénario possible a lieu quand la boîte est étroite (c’est-à-dire peu impactée par les caractéristiques du jeu de données) et à une position haute (meilleure précision moyenne). Au vu des résultats, USTEP apparaît comme l’algorithme le plus robuste et le moins influencé par la nature des jeux de données. Afin de permettre une meilleure reproduction de nos travaux et de les transmettre à la communauté, le code source d’USTEP est disponible sur GitHub.
La version distribuée pour le passage à l’échelle
Le temps de traitement est particulièrement important quand le volume à gérer est grand et que la réponse doit se faire rapidement, comme cela est notre cas. Dans les meilleurs scénarios, USTEP et Drain ont besoin de 5 à 6 heures pour traiter 30 minutes de logs issus de nos infrastructures Cloud, rendant de fait leur utilisation impossible au sein de 3DS OUTSCALE. Cette limitation nous a motivés à proposer une version distribuée de nos travaux.
USTEP-UP est un framework pouvant faire tourner en parallèle plusieurs instances d’USTEP. USTEP-UP se sert d’un load balancer pour équilibrer la charge entre des instances et d’un knowledge manager pour homogénéiser les arbres des instances. Ces deux composantes permettent de ne pas avoir d’interactions entre les instances, rendant alors possible une augmentation à l’échelle (scale-up) par l’ajout de nouvelles instances. Dans le cas d’une diminution du nombre d’instances (scale-down), une méthode de fusion des arbres est proposée.
La structuration de logs au service de la détection d’anomalies
La structuration est une étape clé pour les applications basées sur les logs telles que les outils de recherche rapide et d’indexation (ElasticSearch par exemple). Nos travaux de recherche portent sur la détection d’anomalies où un seul log (ou une séquence) peut nous indiquer que le système est en train d’avoir une défaillance, qu’un bug logiciel se produit ou que la sécurité est menacée.
DeepLog 4 est un algorithme de Deep Learning basé sur des réseaux Long Short-Term Memory (LSTM) proposé par des chercheurs de l’Université d’Utah en 2017. Les réseaux neuronaux sont pratiques pour les logs car ils traitent les messages comme du texte. Dans son cas, DeepLog propose un mécanisme permettant de déterminer les séquences anormales à la fois dans les patrons et dans les variables.
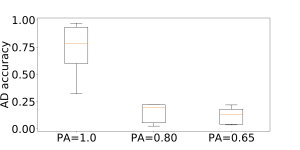
Nous avons utilisé DeepLog, couramment cité dans l’état de l’art, pour étudier l’impact de la structuration sur la détection des anomalies. La figure ci-contre présente la précision de détection des anomalies (AD accuracy) selon la précision de la structuration (PA). Nous observons un impact très négatif pour la détection dans le cas d’une précision de structuration en dessous de 80 %.
En conclusion, les méthodes de structuration sont cruciales pour supporter la détection d’anomalies. Des méthodes comme USTEP et USTEP-UP, scalables, hautement précises et robustes vis-à-vis de l’évolution des systèmes de logs, constituent la première étape vers la conception d’un détecteur d’anomalies basé sur les logs de 3DS OUTSCALE.
Pour aller plus loin, nous vous recommandons la lecture de l’article USTEP: Unfixed Search Tree for Efficient Log Parsing. Proceedings of the 21st IEEE International Conference on Data Mining (ICDM’21).
Découvrez également cette récente présentation des travaux en vidéo !
Références
- Exemples de logs NetApp extraits de : https://docs.netapp.com/ontap-9/index.jsp?topic=%2Fcom.netapp.doc.dot-cm-cmpr-930%2Fevent__log__show.html
- Exemples de logs Cisco extraits de : https://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst3750x_3560x/software/release/12-2_53_se/system/message/3750x/overview.html
- He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree”, in 2017 IEEE International Conference on Web Services
- Du, F. Li, G. Zheng, and V. Srikumar, “Deeplog: Anomaly detection and diagnosis from system logs through deep learning”, in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security