

In this blog post, we will talk about automatic log parsing and its relevance in anomaly detection. This project is the result of a fruitful collaboration between LISITE-ISEP research laboratory and 3DS OUTSCALE. Lately, I had a chance to present my work at the last edition of IEEE International Conference of Data Mining.
As we have previously seen, logs are triggered by computer systems in order to save an event’s history. Thus, event information, such as the executed tasks, the system involved, the severity level, or a part of the system state, are timestamped and archived. For example, the following log line was triggered by the serviceManager regarding a new process:
2020-03-19T15:38:55,977 - serviceManager - INFO - New process started: process x92 started on port 42
Traditionally, logs were used to detect computer failures or to fix development bugs. In recent years, due to the growth of Big Data, logs show the potential for application latency monitoring, security audit reinforcement, or customer journey understanding for Business Intelligence.
In our context, Big Data enables efficient log analysis because of a significant increase of logs produced/stored in our infrastructure (75 % growth in 2018, 50 % in 2019). This is caused both by the natural growth of infrastructure and by the interest sparked by the results. Final -end users encourage higher log production when they grasp how useful the analysis is.
To be ready for real-time analysis, logs require to be structured in order to identify comparable elements. In the example above, we observe some easily recognizable and well-structured fields such as the date (2020-03-19T15:38:55,977), the application (serviceManager) and the severity (INFO). However, we have a free message (New process started: process x92 started on port 42) generated in the code that could change with future software versions.
Let’s see other examples of logs coming from our partners solutions:
NetApp1 :
monitor.globalStatus.ok: The system's global status is normal. vifmgr.portup: A link up event was received on node node1, port e0c.
Cisco2 :
%LINK-3-UPDOWN: Interface Port-channel1, changed state to up %LINEPROTO-5-UPDOWN: Line protocol on Interface Vlan1, changed state to down %SYS-5-CONFIG_I: Configured from console by vty2 (10.34.195.36)
First, we observe that messages format depends on the solution. Second, messages coming from the same solution may match different templates (i.e., an expression such as New process started process * started on port *, showcased earlier). Finally, variables can be numbers or words, given that a word in one template can be a variable in another.
In OUTSCALE infrastructure, log production is provided by the different systems of the stack: our cloud operating system TINA OS, different middlewares, various physical equipment, etc. The structure of log messages is therefore beyond our control. Furthermore, we don’t restrict such a rich source of information with formatting constraints that would hinder the generation. We therefore need a parsing algorithm that is robust enough to handle the behaviors of different systems and their evolution.
Log parsing deals with real time identification of the template and variables for each incoming log with a high volumetry log coming from multiple systems. Although this topic has already been studied, state-of-the-art solutions do not meet our requirements in terms of accuracy, robustness, latency, and scalability.
USTEP: An Evolving Search Tree for Parsing Logs
To meet these accuracy and robustness requirements, we have developed USTEP, a log parsing algorithm based on an evolving tree structure. Tree leaves store templates, and logs descend the tree to find the most suitable leaf. USTEP then selects a template that best represents the processed message. If none fits, a new template is created from current logs. In this process, two aspects are key: the tree descent rules and the evolution of the tree’s structure.
For the descent, USTEP first exploits the assumption that logs with the same template have the same number of words. The rest of the search process is determined by rules discovered by the system regarding important positions for template distinction. Our experimental evaluation supports the relevance of our assumptions, with USTEP being more accurate and robust than state-of-the-art algorithms, with an average accuracy of 93% compared to 90% for Drain3, a solution provided by researchers at the Chinese University of Hong Kong in 2017 and currently considered as a reference.
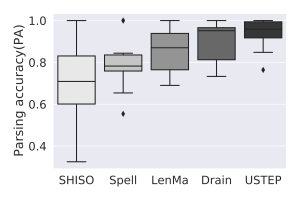
Our evaluation was conducted on 13 free-access data sets coming from different systems (Android, HDFS, OpenStack, etc.). State-of-the-art algorithms have a high variability depending on the data set. This variability is sensitive in a situation like ours where different log systems coexist and evolve independently of our control. In the figure on the right, we present the scatter of 5 algorithms based on the studied data sets. The best possible scenario occurs when the box is of shorter length (i.e., little impacted by the data set’s characteristics) and at a high position (best average accuracy). Based on the results, USTEP appears to be the most robust algorithm and the least affected by the nature of the data sets. To allow for a better reproduction of our work and pass it on to the community, the source code of UTSEP is available on GitHub.
A Distributed Version for Scaling
Processing time is particularly important when there is a large volume to process in a short time, as in our case. At best, USTEP and Drain need 5 to 6 hours to parse 30 minutes of logs from our cloud infrastructure, making them impossible to use at 3DS OUTSCALE. This limitation inspired us to propose a distributed version of our work.
USTEP-UP is a framework that can run several USTEP instances simultaneously. USTEP-UP uses a load balancer to distribute the workload between instances and a knowledge manager to homogenize the trees of the instances. These two components prevent interactions between instances, making it possible to scale up by adding new instances. In the case of a decrease of the number of instances (scale-down), a tree-merging method is available.
Log Parsing at the Service of Anomaly Detection
Parsing is key for log-based applications such as search and indexing tools (ElasticSearch). Our research focuses on anomaly detection where only one log (or sequence) can indicate that the system is malfunctioning or that there is a software bug or a security threat.
DeepLog 4 is a Deep Learning algorithm based on Long Short-Term Memory (LSTM) networks introduced by researchers at Utah University in 2017. Those neural networks are convenient for logs because they process log sequences like text. In their case, DeepLog offers a mechanism that determines abnormal sequences both in templates and variables.
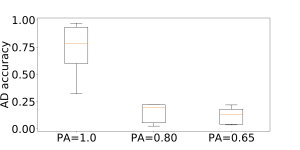
We have used DeepLog, frequently quoted in state-of-the-art research, to study the impact of parsing on anomaly detection. The figure on the right shows anomaly detection accuracy (AD accuracy) according to parsing accuracy (PA). We can observe a very negative impact on detection when parsing accuracy is under 80%.
In conclusion, parsing methods are crucial to enhance anomaly detection. Methods like USTEP and USTEP-UP, which are scalable, highly accurate and robust to log system evolution, are the first step towards an anomaly detector based on 3DS OUTSCALE logs.
For further information, we recommend reading the research article by Arthur Vervaet, Raja Chiky and et Mar Callau-Zori: USTEP: Unfixed Search Tree for Efficient Log Parsing. Proceedings of the 21st IEEE International Conference on Data Mining (ICDM’21).
Also, watch Arthur’s vidéo presentation to learn more!
References
- NetApp log examples extracted from: https://docs.netapp.com/ontap-9/index.jsp?topic=%2Fcom.netapp.doc.dot-cm-cmpr-930%2Fevent__log__show.html
- Cisco log examples extracted from: https://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst3750x_3560x/software/release/12-2_53_se/system/message/3750x/overview.html
- He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree”, in 2017 IEEE International Conference on Web Services
- Du, F. Li, G. Zheng, and V. Srikumar, “Deeplog: Anomaly detection and diagnosis from system logs through deep learning”, in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security
Arthur Vervaet is a Big Data PhD student at 3DS OUTSCALE since early 2020.
Raja Chiky is head of innovation and entrepreneurship at the Institut Supérieur d’Electronique de Paris (ISEP).
Mar Callau-Zori has a PhD in computer science and is data lake officer at 3DS OUTSCALE.