

At the end of 2021, I started a collaborative PhD, based on a partnership between 3DS OUTSCALE and the École Normale Supérieure de Lyon (ENS de Lyon), represented by my advisor Alain TCHANA, who was awarded a prize dedicated to young French-speaking researchers in 2022 and head of the Computer Science Department at the ENS de Lyon. In this article, I would like to give an introduction to my thesis topic on storage virtualization.
What is Computer Storage?
There are mainly two types of memory in computers: volatile and persistent memory. Volatile memory (or just memory) is extremely fast; thus, it stores temporary data while running a program: the program itself, the manipulated data or some metadata. Persistent memory (or storage) is slower, but it is recoverable after your computer is stopped. Files stored in persistent memory include both user files (documents, pictures, etc.) and system files, for example the operating system and all installed programs.
In the case of this PhD thesis, we focus on the last one, persistent storage. Let’s see why.
How Do We Know if a System Needs Improvement?
Before even talking about improving a system (here, storage at a datacenter scale), we need to make sure that the system requires improvement. This can be done by running a benchmark (or multiple ones), a program that will put the studied system under stress , and then measure how well the system behaved under that stress. Comparing the performance of different systems (different hardware, applications, operating systems, versions of the same application, etc.) within one benchmark allows us to determine which one is the more performant.
There are two kinds of benchmarks: micro- and macro-benchmarks. The first category includes relatively basic programs that will focus on stressing a single component of the system; for instance, fio is a simple program that generates stress on the system’s storage. The second category, macro-benchmarks, aims at testing the overall performance of the system and therefore tends to offer a more realistic picture. They generally consist of a real application that is run under a reproducible workload.
Thus, macro-benchmarks can help make sure that the overall system works fine, and micro-benchmarks help point out the problems more precisely. One of the problems we tackle in this PhD research is the lack of realistic benchmarks for storage in datacenters. The only one to our knowledge is CNSBench, but it was designed for clients of a cloud who want to compare providers. Though, in order to improve our systems, we need to benchmark from the provider’s point of view.
Now let’s dive into the core of the topic: storage performance in modern systems.
Storage is a Bottleneck in Modern Systems
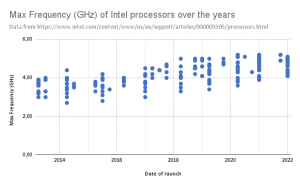
In recent years, tremendous progress has been made in computer systems performance. This article provides a great insight into how computing power has evolved as of 2017. By looking at data provided by Intel about their Core processors, one can guess that the growth in computing power is not even close to stopping. For instance, in the graph below, we see that the most performant (thus expensive) processors launched by Intel in 2013 are slower than the less performant ones released recently (late 2021 / early 2022). Note that the data used for this graph only includes the frequency of a single core, and does not even take into account the fact that the number of cores in processors has also been increasing.
Unfortunately, modern cloud systems are not able to fully benefit from these improvements. In fact, due to the overhead of virtualization, there is a slowdown when it comes to running a benchmark in the cloud compared to the same benchmark run on bare metal (which means on the computer without virtualization). In the following figure, we show the results of an experiment we made to get inspiration for our work. We ran different micro-benchmarks in 4 different environments: bare metal, a custom private cloud (VPC), a Microsoft Azure VM and an AWS VM. We express the results of the three latter in terms of slowdown compared to the bare metal experiment. The benchmarks are NPB (CPU intensive), Stream (memory intensive), Netperf (network intensive), dd and fio (both storage intensive, but more precisely throughput and latency intensive, respectively). For fairness, the Microsoft Azure and AWS virtual machines specifications were chosen to be as close as possible to our server’s specifications.
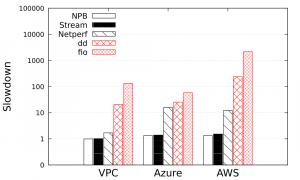
The interpretation of the results is quite straightforward: in public clouds, the slowdown of CPU and memory intensive benchmarks is almost negligible, while storage intensive benchmarks are between 10 and 1000 times slower.
Therefore, as soon as an application is storage intensive, its overall performance is limited by storage capabilities. From our perspective, it can be quite problematic when you realize that many applications you would want to run in the cloud are storage intensive: web servers (Apache, Nginx, …), mail servers (Zimbra, Roundcube, …), data analysis (MapReduce, Spark, Kafka, …), databases (MySQL, MongoDB, RocksDB, Redis, …), etc.
Now let’s see how storage is handled in modern Clouds?
The Storage Stack
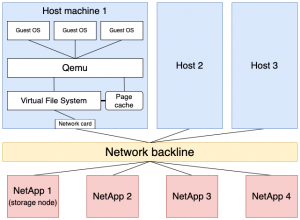
The storage stack is defined as the set of elements that take action one after the other when processing an I/O request (I/O stands for storage Input/Output). In the case of a bare metal computer, the storage is basically composed of a program that requests the I/O operation, the operating system, the filesystem, and the hardware device. In the cloud, the structure is much more complex, as you can see in the figure above. Requests issued by the guest OS (the OS of the VM) are intercepted by the hypervisor (the program responsible for the virtual machines management), then are treated by the host OS (the OS of the server on which the VMs are running), and then are sent to the host filesystem to be written on the drive. However, the storage devices are located in a different server, which means that the request must go through an extra step, the network, before finally reaching the storage server (in our case, NetApp storage array) and the drive on which it will be written.
On the other hand, when a VM uses its CPU, it actually uses a virtual CPU (vCPU) provided by the hypervisor. The hypervisor can emulate a CPU, even one that is different from the actual CPU of the host OS. In that case, the emulation adds an extra overhead. If we are looking for more efficiency, the vCPU can also be directly mapped to the actual CPU, without emulation or extra steps. This is what we call passthrough, because it acts as if the CPU were directly used by the VM. In that case, the vCPU has almost the same speed as the actual CPU.
However, for storage, passthrough is often not desirable. First, you might not want the VM to have access to anywhere in the storage, so it requires extra isolation. Second, virtual disks are often stored in files using a special format: such as QCOW2 for Qemu. This format allows lightweight snapshotting, which improves efficiency and eases storage management. But it also has drawbacks, and one of them is the need for remapping the addresses from the guest OS to addresses in the QCOW2 file. Thus, Qemu’s intervention is necessary to operate the translation. Furthermore, the storage is distant (not on the same server) and shared, so storage passthrough is in fact not even possible in this type of datacenter.
This difference mostly explains why the storage virtualization is so much harder and less efficient than the CPU or memory.
Then, How do We Improve Storage Performance?
As you can guess, the high complexity of the storage stack in a cloud provider’s architecture leaves some space for improvement. We can choose to focus on any part of this stack, for instance, the hypervisor, or the storage server. We can also try to be more disruptive and propose changes that could be applied to the whole stack, while imagining new architectures. For instance, a new datacenter architecture is becoming popular: the hyper-converged architecture, in which the storage is placed closer to the processor. Still, the reason why hyper-converged architectures are gaining popularity is its maintenance which is easier, although there is still no evidence of its positive or negative impact on the overall system’s performance.
In the specific context of my PhD, I will be working on both the current architecture and existing alternatives. The three main components of my PhD would be:
- Create a benchmarking system to measure the performance of a cloud storage infrastructure. This should allow us to shed light on the different bottlenecks that can exist in the whole storage stack.
- Focus on the problems we have detected in Qemu. We have already noticed that Qemu, and the QCOW2 format (which is used to store the drives of the VMs), are not made to be performant at the scale of a cloud infrastructure.
- Explore and compare different storage stack architectures, to see if one performs better than the others.
These three parts are far from being isolated from each other: the benchmarking system will be useful for detecting issues in Qemu, and vice versa searching for issues in Qemu will give us ideas for improving the benchmark. The third part will require a deep understanding of existing storage types of architecture, and the first two parts of the PhD will help build expertise.
The Final Word
In conclusion, we noticed through our experiments that storage is a bottleneck in many applications running in the cloud. The goal of this project is to find how to optimize storage performance in a cloud environment, and to provide the tools required to carry out this analysis beforehand.
I presented this project at the Eurosys Doctoral Workshop, where I discussed it with other PhD students from all over the world and their supervisors, as well as other experts on the topic. You can find the slides of the presentation here attached and the video presentation in French and in English (below).