

In this post, we will share the journey of developing a Cluster API provider. Cluster API is a Kubernetes operator based on the Kubebuilder[1] framework.
The objective of Cluster API is to reduce the complexity of managing and maintaining a cluster, to ease the provisioning of its infrastructure on cloud and on-premise with a Kubernetes-style API. It automates the cluster lifecycle of Kubernetes clusters (create, upgrade, delete) and manages a massive fleet of Kubernetes clusters. Users can also choose the bootstrapper provider like kubeadm or microk8s and infrastructure providers.
In this article, you will learn how to build your own Cluster API provider:
- You will see the architecture of a Cluster API.
- The main components you must develop.
- Some focal points you must be careful of.
- You will learn about the unit, functional and E2E tests for Cluster API.
Architecture of Cluster API infrastructure provider
a. Choice of Architecture
It is important to define the default target cluster architecture based on services like machines, networks, etc. [1] [2] [3] [4]
For example, we have chosen to adopt a single AZ (availability zone) architecture with separate master, worker, and public subnets.
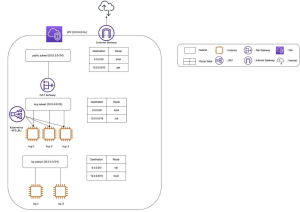
b. Build your application
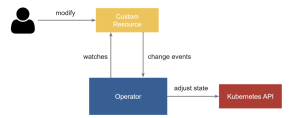
When creating a provider for Cluster API, it is important to follow these rules. The first step is to create an operator using Kubebuilder to create the infrastructure controller that will be used to manage your cluster provider object and machine provider object.
Kubebuilder is a framework to quickly build and publish Kubernetes API and controllers using CRDs (Custom Resource Definitions).
Futhermore, Kubebuilder will generate your CRD based on your API definition, the Kustomize[2] YAML deployment of your controller and create the skeleton for the reconcile function.
Each time you change the API definition, you will use Kubebuilder to regenerate the CRD and the Kustomize YAML deployment. For more information, please refer to the Cluster API Developer Guide[3].
c. Create Provider contract
In order to publish your Cluster API provider, you will need to create a provider contract with:
- metadata.yaml: a map file between provider release and Cluster API release
- components.yaml: a YAML file that contains all the components for your provider installation
- cluster-template[4]: a YAML file with all the objects needed in order to create your cluster through environment variables
For example, you can find a release[5] of Cluster API at OUTSCALE.
Kubernetes API style with Custom Resource Definitions, controller and cloud scope
Your Cluster API provider will be based on the Kubebuilder framework utilizing Kubernetes API with Custom Resource Definitions (CRDs), controllers and cloud scope.
Furthermore, the cloud scope is the method getter and setter for each cluster and each machine object.
a. Kubernetes-style API with Custom Resource Definition
The next step is to define your Kubernetes-style API for each controller (machine and cluster) based on services like VM, network, etc. which are controlled through your provider’s resource API in order to create a cluster with machines.
The idea then is to build into the cluster controller the API definition based on the parameters of each component that is part of the cluster, such as network, loadbalancer, public IPs, etc.
In our provider, we’ve chosen to define OscNetwork in order to handle each cluster component and its parameters.
It is composed of LoadBalancer, Net, Subnets, InternetService, NatService, RoutesTable, SecurityGroups and PublicIps.
For a machine controller, the best is to build into it the API definition of each component that will consist of a machine such as a Virtual Machine, disks, SSH Keys, etc.
We have decided to define OscNode to handle each machine component’s parameters composed of VM, Image, Volumes, KeyPair.
There are some mandatory status fields for the cluster controller:
- “Ready” which is a boolean field that is “true” when the infrastructure is ready to be used.
- “ControlPlaneEndpoint” which is the endpoint used to expose the targeting cluster API server.
There are also some mandatory fields for a machine controller:
- “Ready” which is a boolean field that is “true” when the bootstrap config data is ready and ready to be used.
- “DataSecretName” is a string field which is a reference to the secret name that is stored generated bootstrap data.
b. Infrastructure Controllers
You need to implement the cluster infrastructure controller and the machine infrastructure controller within the infrastructure controller[5] .
The cluster infrastructure controller manages the K8s cluster lifecycle, and the machine infrastructure controller manages the K8s machine lifecycle.
At OUTSCALE, the cluster infrastructure will create a cluster with load balancer, net, subnet and route table and it will expose the cluster endpoint.
After the infrastructure is provisioned, the machine infrastructure will create a virtual machine with a bootstrap mechanism.
It is possible to create a cluster reconciliation function (“reconcileDelete” and “reconcile”) for each component in the cluster infrastructure controller and the machine infrastructure controller.
As a controller, you must implement a control loop that observes the desired state of the object, checks the difference between the current state and the desired state, brings the current state in line with the desired state and it repeats continuously.
c. Webhooks
Admission webhooks are controlled by the admission controller.
Admission webhooks are HTTP callbacks which get admission requests, process them and send admission responses. They arbitrate the API request route path between Kubernetes components.
When you change an object with an operation like creation, deletion, etc. the mutation webhook will modify the object and validation determines which custom policies are accepted or rejected.
There are three webhooks that can be carefully implemented in your Cluster API provider to avoid impacting the system:
- Validation webhook which is used to validate user webhook and which is an implementation of Kubernetes webhook.
It will get an admission request which has an object and accepts or denies the request with a reason message.
- Default webhook which is used to set default values, and which is an implementation of Kubernetes mutation webhook.
- Conversion webhook to have Cluster API to manage multiple versions of the API.
Unexpected Behavior
a. Check API parameters
It is necessary to check that the provider’s resources APIs are never called with bad parameters (resources such as VM, network, load balancer, etc.) If you send bad parameters to the controller, it should be stopped before launching the provider resource API call.
It avoids having the controller fail over and over on the control loop with bad API call parameters that will keep creating resources from the previous successful API call for each loop.
b. Two clusters instead of one
Depending on your provider resource API, you should store the ID of your provider resource (e.g., VM, network, load balancer, etc.) of each cluster, each machine[6] so that you can use this API to create provider resources on the first reconciliation loop, validate your object still exists in both Kubernetes and your provider on the second reconciliation loop and thus avoid recreating this provider resource.
It should be stored in your CRD with a status parameter which will contain a map with resourceName and resourceId.
c. Webhook behavior
Your cluster template must be defined with the minimum of parameters as it should use default parameters. Each component parameter can be overridden.
When you set your webhook, you should only validate the parameters which are in the cluster-template.
Cluster API Unit and Functional test
It is time then to create a test pyramid with unit-tests and functional tests. Cluster API advises you how to create unit and functional tests which are strongly suggested for Cluster API providers.
a. Unit Tests
With unit tests, you can mock only the cloud scope instead of mocking your API, so you mock functions which call the API instead of mocking the API.
In fact, there is no need in mocking the API but only mock some functions which call the API.
With unit tests, we use “go testing package”[6] and “mock” to validate the expected behavior of each function individually.
b. Functional tests
It is possible to create functional tests for cluster controllers to verify the creation and the deletion of a cluster.
It is also possible to create a functional test for a machine controller with a cluster controller to verify the creation and deletion of individual machines.
In those tests, you don’t have “kubeadm” bootstrap configuration[7] so it will only test one machine and cluster controller creation and destruction.
In Cluster API, it is necessary to define the kubeadm bootstrap configuration template which will be used by the bootstrap controller[8] to generate a cloud-init[9] configuration. In order to validate the cloud init configuration which will be generated by the bootstrap controller, you can add a test which creates a machine with the same cloud initialization configuration (or bootstrap data) as the one defined in cluster templates.
Furthermore, you will test that your machine has the same behavior as a master node, but it is not a master node[10] because you don’t use a kubeadm bootstrap configuration.
Each Cluster API bootstrapper like kubeadm, rke, and microk8s will create and update nodes using cloud-init. In fact, the configuration of the node will be in cloud-init format generated by the bootstrap controller using the bootstrap K8s config object.
5. Cluster Api E2E Tests
a. Validate real use case
Creating E2E tests based on the Cluster API framework allows us to check the good behavior on Cluster API in an environment similar to a real production environment. Cluster API advises how to create E2E tests which are strongly suggested for Cluster API providers.
E2E tests help validate that your Cluster API provider controller has the expected behavior with simple use-cases such as upgrade, remedication, high availability control plane.
E2E test will use all the controllers[11] (cluster, machine, bootstrap, control-plane) of cluster API to test the behavior of the previously mentioned use-cases.
For example, we have used a fixed private IP as a virtual machine input parameter. However, if a machine is rolling update it is not possible to have two virtual machines with the same private IP.
b. Missing CCM
After we launched our first E2E test (ApplyClusterAndWaitTemplate) with both machine and cluster infrastructure controller, we found that this test had never checked the status of pod or node.
As we discovered afterwards, the cloud controller manager is mandatory for a Cluster API to untaint node.cloudprovider.kubernetes.io/uninitialized from nodes.
To have a cluster and nodes ready, you need to set cni (calico, kube-router, etc.) and remove your node taint node.cloudprovider.kubernetes.io/uninitialized from nodes as Cluster API uses a cluster-provider-id to turn your machine into a running node with ccm (cloud provider, metallb, etc.) or untaint nodes one by one.
c. Bootstrap Cluster
The E2E test framework from Cluster API can be used to have a list of E2E tests. Although, there are several functions that you can call in the framework (ClusterUpgradeConformanceSpec, MachineRemediationSpec, etc.) that need to have a management cluster to access some object statuses (the status of machineList).
It is possible to launch your E2E tests with the creation of K8s cluster with kind[12].
d. Conformance test
Adding a conformance test that uses sonobuoy[13] to validate your cluster allows you to understand what is missing in your configuration or architecture.
This, for example, helped us understand that we needed to open a bgp port (179) for calico[14].
Conclusion
Creating your own Cluster API provider is a long journey that should be overseen by a Cluster API project and supported by comprehensive documentation.
In this post, we saw that the steps included choosing architecture, setting your API definition, creating the skeleton with Kubebuilder, then implementing your controller to manage your provider resources and create unit, functional and E2E tests.
OUTSCALE Cluster API provider[15] is available to deploy a fleet of clusters at OUTSCALE with kubeadm[16].
Currently, our Cluster API provider[17] is only available in a mono availability zone. One of the next major features will consist of having our cluster available on two availability zones and having integration with new bootstrappers like microk8s[18] and rke[19].
[1] https://github.com/kubernetes-sigs/kubebuilder
[2] https://kustomize.io/
[3] https://cluster-api.sigs.k8s.io/developer/guide.html
[4] https://cluster-api.sigs.k8s.io/developer/providers/contracts.html
[5] https://github.com/outscale-dev/cluster-api-provider-outscale/releases/tag/v0.1.4
[6] https://pkg.go.dev/testing
[7] https://cluster-api.sigs.k8s.io/tasks/bootstrap/kubeadm-bootstrap.html
[8] https://cluster-api.sigs.k8s.io/developer/architecture/controllers/bootstrap.html
[9] https://cloud-init.io/
[10] https://cluster-api.sigs.k8s.io/developer/architecture/controllers/machine.html
[11] https://cluster-api.sigs.k8s.io/user/concepts.html
[12] https://kind.sigs.k8s.io/docs/user/quick-start/
[13] https://github.com/vmware-tanzu/sonobuoy
[14] https://projectcalico.docs.tigera.io/about/about-calico
[15]https://cluster-api-outscale.oos-website.eu-west-2.outscale.com/topics/get-started-with-clusterctl.html
[16] https://github.com/kubernetes-sigs/cluster-api
[17] https://github.com/outscale/cluster-api-provider-outscale
[18] https://cluster-api.sigs.k8s.io/tasks/control-plane/microk8s-control-plane.html
[19] https://github.com/rancher-sandbox/cluster-api-provider-rke2
Glossary
outscale-bsu-csi-driver: Expose block storage (BSU) to container workload for container orchestration.
BSU: Block storage unit to have the storage capacity (in GiB) you provisioned a standard/gp2/io1 volume.
CCM: Cloud provider manager to have load balancer service which is associated with LBU.
LBU: Load balancer unit to have a running load balancer in public cloud or in a Virtual Private Cloud (Net)
OUTSCALE: OUTSCALE is a French cloud provider that offers Cloud services on robust and secure IaaS infrastructures, available on demand.
OscMachine: The OUTSCALE machine controller.
OscMachineTemplate: The OUTSCALE machine template.
OscCluster: The OUTSCALE cluster controller.
OscClusterTemplate: The OUTSCALE cluster template.
CRD: (Custom Resource Definition) Add custom object to Kubernetes resource which included an open-api schema.
Kustomize: Templating to customize applications deployed on Kubernetes.
Kubernetes operator: Application specific controller to extend functionality of Kubernetes api to create, manage and delete complex applications.
Microservices: Microservice are an architectural pattern for applications to be independently deployed, loosely coupled, highly available and handle simple business capabilities, owned by a small team.
Bootstrap Provider: It creates a bootstrap data used to bootstrapping a Kubernetes node.
CNI: (container network interface) Plugin which configures Kubernetes network.
E2E test: (End to end test) Test the entire application to have the expected behavior of the application.
ProviderID: A cloud provider ID to identify the machine.